
Как я ускорил загрузку сайта с позорных 5 секунд до 1.6 секунды, когда ни один из обычных способов уже не работал.
Кратко суть
Если тормозит сайт на Drupal:
- Что тормозит - фронт (скрипты, картинки...) или бэк (хостинг, база данных)?
- Проверяем, установлены ли необходимые модули для ускорения загрузки сайта.
- Всё еще тормозит? В 99% случаев виноваты Views. Ставим модуль Web Profiler и ищем с его помощью медленные запросы.
- Иногда помогает добавить недостающие индексы в БД.
- Индексы не помогли? Модифицируем медленные вьюхи:
- заранее собираем аргументы,
- записываем их в кэш или базу,
- пробрасываем во вьюху с помощью хуков.
- Profit.
Ниже подробнее.
▲Влияет ли скорость загрузки сайта на SEO?
Краткий ответ - да.
Не так сильно, как кажется.
Но пользователи любят быстрые сайты.
Очень много тормозящих сайтов занимают топы. Но это говорит лишь о том, что они попали туда благодаря другим, более сильным факторам.
Скорость загрузки прежде всего бьёт по юзабилити сайта - пользователи не любят тормозящие страницы, будут уходить с сайта, начнут проседать ПФ и этот снежный ком проблем начнёт расти. Чтобы они не уходили, я даже не знаю, насколько ценной и уникальной должна быть у Вас информация, чтобы юзеры терпели боль и страдания.
Одно из главных правил успешного SEO - забыть про SEO и думать о посетителях.
▲Почему тормозит Drupal?
Drupal из коробки предлагает шикарные механизмы кэширования. Но всё будет работать только в том случае, если сайт маленький или средний.
Чтобы было понятней, внесу ясность:
- маленький сайт - сотни сущностей,
- средний сайт - десятки тысяч сущностей,
- крупный сайт - сотни тысяч и более сущностей.
Когда на сайте мало материалов, пользователей и трафика, можно даже не включать кеширование.
Но если скорость отдачи страниц начинает расти пропорционально размеру базы и нагрузке - это надо исправлять. Любой сайт должен открываться одинаково быстро, будь на нём тысяча или десять миллионов страниц.
Самые частые причины медленной работы Drupal
Причин может быть еще больше, редкие случаи расписывать не буду, расскажу о самых основных.
- Тяжелые представления, они же Views. Шикарный модуль, но автоматическая генерация запросов к БД генерирует не всегда оптимальные варианты. Плюс фильтрация или сортировка могут происходить по непроиндексированным полям.
- Неправильная настройка хостинга. Сюда входит настройка необходимых модулей PHP, конфиги MySQL, Nginx, Apache и тд.
- Слабое железо хостинга. В зависимости от размера сайта и нагрузки, требования к железу могут возрастать.
- Подгрузка тяжелых скриптов, например реклама, счетчики, виджеты со сторонних сайтов и тд.
- Криво настроенные или самописные модули. Это происходит реже, но имеет место быть. Например какой-то модуль долбится к API, которое недоступно на данный момент. Или те же медленные запросы к БД. Надо регулярно делать ревизию, а всё тяжелое должно обрабатываться фоновыми задачами.
Условно загрузку сайта можно разделить на две части:
- back - сбор и формирование данных на серверной стороне,
- front - рендеринг на пользовательской стороне, всё с чем связана работа в браузере, например загрузка html, скриптов, стилей, картинок и тд.
Первый шаг - понять в какой части тормозит сайт, сделать это легко:
- Проще всего разобраться с фронтом - запускаем Lighthouse в браузере Chrome и смотрим на отчёт, в котором будет подробная информация о причинах медленной работы. Всё неплохо задокументировано со ссылками на различные гайды. Берём и делаем.
- Если тормозит задняя часть, обычно это понятно по длительному ожиданию ответа от сервера. Здесь не всё так просто и однозначно.
Модули для ускорения загрузки страниц Drupal
Ниже список из минимального мастхев набора для любого сайта.
В ядре:
- BigPipe - не требует настройки (zero configuration), технология ускорения загрузки страниц, разработанная в Facebook.
- Internal Dynamic Page Cache, Internal Page Cache - кэшируют страницы с динамическим содержанием.
Кастомные:
- Advagg - advanced CSS/JS aggregation, сжимает и объединяет CSS/JS файлы, сокращая, как количество запросов к серверу, так и размер загружаемых данных.
- Redis - переносит все кэши в Redis (должен быть установлен на сервере).
- Memcache - альтернатива Redis.
- Warmer - разогревает кэш сайта, чтобы юзеры всегда видели закэшированную версию страниц. Может запускаться, как по крону, так и драш командой.
- Boost - для Drupal 7, на момент публикации материала для более поздних версий не существует. Делает "слепок" каждой страницы в виде статичного HTML, что в разы ускоряет их загрузку.
Дополнительно:
- В PHP необходимо включить модули APCU Cache и OP Cache.
- Сервер должен быть правильно настроен:
- пример конфига для Nginx - https://www.nginx.com/resources/wiki/start/topics/recipes/drupal/
- пример конфига для Apache - https://www.drupal.org/docs/7/managing-site-performance-and-scalability/optimizing-drupal-to-load-faster-server-mysql-caching-theming-html#s-apache-settings
- MySQL - https://www.drupal.org/docs/7/managing-site-performance/optimizing-mysql
- Так же можно перевести сайт на Cloudflare и включить в нём Rocker Loader для ускорения загрузки скриптов. А в платной версии можно еще сильней кэшировать страницы для анонимов (привязка к кукам авторизации на сайте).
Что делать, если сайт всё равно тормозит?
Если установлены все перечисленные выше модули, а страницы всё равно долго открываются, то это значит, что нужна дополнительная работа.
В моём недавнем случае, страниц сайта было несколько миллионов. Их было настолько много, что место, выделенное под кэш не могло уместить все контексты кэша. Новый кэш постоянно переписывал старый. Увеличить выделенный размер под кэш - не вариант. Пользователи часто попадали на страницы, которых в кэше нет. Тормозило всё.
Дебажим.
Первым делом ставим модули:
- Devel - полезные вспомогательные функции для разработчиков, в том числе расширенное логирование и дебаг, требуется для других модулей.
- Web Profiler - дебажит загрузку любой страницы и выявляет медленные запросы. Зависит от Devel.
Порядок работы:
- Включаем оба модуля.
- Сбрасываем кэш.
- Внизу каждой страницы появится панель разработчика.
- По завершению работ необходимо выключить оба модуля, так как Web Profiler будет записывать по умолчанию каждое посещение в БД и можно очень быстро засрать базу данных. Либо периодически удалять старые логи.
Далее - переходим на медленную, незакешированную страницу.
Это важно: надо сбросить кэш перед анализом! Смысла смотреть на cтраницу из кэша нет.
В нижней панели, которую добавил профайлер, будет вкладка Database.
Пример незакешированного запроса:
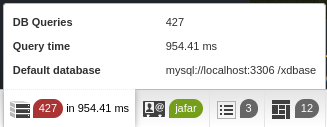
Та же страница, но уже из кэша:
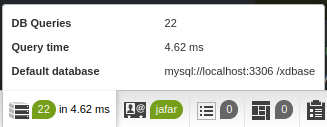
- 427 запросов и 965 мс, когда страницы нет в кэше,
- 22 запроса и 4.62 мс для страницы из кэша.
Как видите, когда страница попала в кэш, то дебажить там особо нечего. Нужно разбираться с тормозами еще ДО попадания в кэш.
Как сказал знакомый разработчик:
Кэшировать медленные страницы - это всё равно, что заметать мусор под ковёр.
Страницы должны быстро открываться и без кэша.
Далее кликаем на эту вкладку Database в панели и переходим на страницу обзора запросов.
В самом верху будет фильтр, в Slow queries выбираем Yes - показать только медленные запросы.

И смотрим на результат, в зависимости от которго будет несколько вариантов дальнейших действий.
- Копируем запрос, идём напрямую в нашу БД и запускаем его с припиской EXPLAIN в самом начале.
- Смотрим, анализируем, можно ли добавить дополнительные индексы.
- Если ничего не понятно, табличку с результатом explain, сам запрос, а так же список текущих индексов из БД можно скопировать в Chat GPT или Gemini и попросить объяснить, какие индексы имеет смысл добавить в БД.
- Добавляем недостающие индексы, если таковые требуются.
После этих манипуляций повторяем процедуру, сбрасываем кэш, смотрим Web Profiler, анализируем запросы.
Помогло? Супер!
Нет? Ныряем глубже...
Внимание: прежде чем продолжить, сделайте резервную копию данных, особенно ваших вьюх. Либо все манипуляции производите на тестовом окружении, а если такого нет, то создайте новую вьюху, которая не будет влиять на текущее отображение на Вашем сайте.
▲Ускоряем Views
Я лишь в общих чертах обрисую концепцию.
Для примера буду использовать представление, которое использует модуль Similar by terms.
Забегая вперёд, используя описанный подход, удалось увеличить скорость загрузки этой тяжелой вьюхи с 2-3 секунд до нескольких десятков миллисекунд. И это результат без кэша!
Самая медленная часть работы Views - сбор списка необходимых ID сущностей для их последующего рендеринга. Этот список формируется на лету в момент обращения к представлению и в зависимости от сложности выборки и количества полей, по которым эта выборка происходит, может занимать много времени.
Но что если немного переосмыслить эту концепцию и скормить вьюхе уже готовый список ID (аргументов)?
Кратко схема работы такая:
- собираем аргументы заранее и записываем их куда-то,
- в момент вызова подходящей view - подставляем уже готовые аргументы, а не собираем их на лету.
Место хранения аргументов может быть выбрано в зависимости от задачи. Можно положить данные в Redis, если их не много и они часто меняются, либо по классике - в кастомную таблицу БД.
Собираем аргументы
У нас есть вьюха, которая тормозит. Надо засунуть в неё уже готовые аргументы, тогда она будет работать быстро.
Но откуда взять правильные аргументы?
Самый простой вариант: копируем запрос прямо из нужного представления и переносим его в свой модуль.
Как составлять запросы в друпале я здесь рассказывать не буду, так как тема эта слишком обширная. Могу лишь показать пару примеров и посоветовать годный мануал.
Либо, опять же, если лень разбираться, копируем сырой MySQL запрос в Chat GPT и просим его составить друпал-стайл код. Изи.
Например, код, который собирает похожие на текущий материалы:
public function getSimilar(int $nid): array
{
$terms = $this->getNodeTerms($nid);
if (empty($terms)) {
return [];
}
$excluded = $this->getAllExceptCategories();
$conditions = [];
foreach ($excluded as $exId) {
$conditions[] = sprintf("node__field_app_type.field_app_type_target_id = '%d'", $exId);
}
$finalAppTypeCondition = implode(' OR ', $conditions);
$query = \Drupal::database()->select('node_field_data');
$query->leftJoin('node__field_app_type', 'node__field_app_type', "node_field_data.nid = node__field_app_type.entity_id AND ({$finalAppTypeCondition})");
$query->innerJoin('node', 'node', "node_field_data.nid = node.nid");
$query->leftJoin('taxonomy_index', 'taxonomy_index', "node_field_data.nid = taxonomy_index.nid");
$query->leftJoin('node__field_rating', 'node__field_rating', "node_field_data.nid = node__field_rating.entity_id AND node__field_rating.deleted = 0");
$query->addField('node_field_data', 'nid', 'similar_nid');
$query->addField('node__field_rating', 'field_rating_value','rating');
$query->addExpression('COUNT(node.nid)', 'similarity_score');
$query->condition('node__field_app_type.field_app_type_target_id', NULL, 'IS');
$query->condition('taxonomy_index.tid', $terms, 'IN');
$query->condition('node.nid', $nid, '!=');
$query->condition('node_field_data.type', 'movie');
$query->condition('node_field_data.status', 1);
$query->condition('node_field_data.langcode', 'en');
$query->groupBy('node_field_data.nid');
$query->groupBy('rating');
$query->orderBy('similarity_score', 'DESC');
$query->orderBy('rating', 'DESC');
$query->range(0, self::LIMIT);
return $query->distinct()->execute()->fetchAllAssoc('similar_nid', PDO::FETCH_ASSOC);
}
Не копируйте этот код бездумно! Это лишь пример, собранный из запросов, сконструированных через Views. Там есть над чем поработать и оптимизировать, но речь сейчас не об этом.
Пояснения:
- $this->getNodeTerms($nid) - собирает id терминов из нужных словарей,
- $this->getAllExceptCategories() - исключает id определенных терминов.
Меняем настройки View
Для этой вьюхи у меня был создан блок, с кучей правил фильтрации. Их все надо выкинуть.
- Удаляем все критерии фильтрации (Filter criteria). Если сайт мультиязычный и нужно отображать правильные ссылки на текущий выбранный язык сайта, то можно оставить критерий Content: Translation language (= Interface text language selected for page).
- Удаляем правила сортировки. Сортировка будет задана заранее.
- В контекстных фильтрах оставляем только Content ID > Provide default value > Content ID from URL - это нужно для определеня id ноды, но не обязательно. Эту логику так же можно вынести в код и удалить контекстный фильтр. Всё ситуативно.
Итак, у нас получилась простая вьюха, которая в таком виде будет выводить текущую ноду - это мы исправим в коде.
Сохраняем, закрываем.
Где хранить аргументы?
Два основных места хранения:
- Redis - для маленьких объемов, а так же данных, которые часто меняются, их не жалко потерять и легко восстановить. Хранить в нём можно, конечно, всё, что угодно.
- БД - золотая классика. Можно использовать в любой непонятной ситуации.
Для текущего случая аргументы записываю в связанную таблицу similar_nodes:
CREATE TABLE `similar_nodes` (
`nid` int(11) NOT NULL,
`similar_nid` int(11) NOT NULL,
`similarity_score` int(11) NOT NULL,
`rating` float NOT NULL
)
Пояснения к таблице:
- nid - текущая нода,
- similar_nid - похожая нода,
- similarity_score - оценка сходства (количество совпадений),
- rating - рейтинг материала (нужно для сортировки при выводе),
Индексы:
- составной уникальный индекс из двух полей nid и similar_nid, чтобы исключить повторения одинаковых пар,
- обычный индекс по полю nid, чтобы быстро искать нужную ноду.
Пример данных из таблицы:
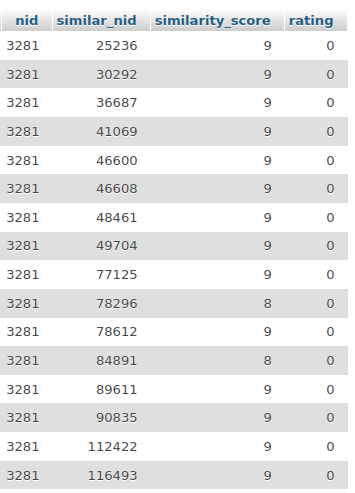
По id ноды находим id других похожих нод. Данные готовы, не надо ничего дополнительно проверять.
Далее сделал Drush команду, которая в цикле обошла все материалы сайта и записала данные в связанную таблицу:
/**
* @validate-module-enabled mymodule
*
* @command mymodule:similar-generate
* @throws \Exception
*/
public function similarGenerate(): void
{
ini_set('memory_limit', '2048M');
$nids = $this->similarNodesService->getNids();
$count = count($nids);
$this->output->writeln(sprintf("Found %d node ids", $count));
$bar = new ProgressBar($this->output, $count);
$bar->setFormat('debug');
$bar->start();
foreach ($nids as $nid) {
$similar = $this->similarNodesService->getSimilar($nid);
if (empty($similar)) {
continue;
}
try {
$this->similarNodesService->add($nid, $similar);
} catch (\Throwable $e) {
$message = sprintf("Node: %d. Error: %s", $nid, $e->getMessage());
Drupal::logger('similar_nodes')->error($message);
}
$bar->advance();
}
$bar->finish();
}
SimilarNodesService - мой кастомный сервис, который инжектится в конструктор драш команд.
Если не знаете, как инжектить свои сервисы, то можно не заморачиваться и запихнуть все функции в .module файл. Да, не очень красиво и удобно будет, но вполне жизнеспособно.
То же самое про создание своей драш команды - погуглите, там всё просто.
А объяснять смежные темы я в этом материале не хочу, и так уже многобуков получается.
getNids() - выдаёт id необходимых материалов.
Ключевой момент - запись в бд через $this->similarNodesService->add($nid, $similar):
public function add(int $nid, array $data): void
{
\Drupal::database()->delete('similar_nodes')->condition('similar_nodes.nid', $nid)->execute();
$insert = \Drupal::database()->insert('similar_nodes');
foreach ($data as $item) {
$insert->fields(['nid', 'similar_nid', 'similarity_score', 'rating']);
$insert->values([$nid, (int) $item['similar_nid'], (int) $item['similarity_score'], (float) $item['rating']]);
}
$insert->execute();
}
Тут всё максимально просто - старые данные текущей ноды удаляются, новые записываются.
Полный обход командой занимает более 3-х суток, поэтому пришлось сделать запасной механизм записи отсутствующих данных в момент вызова View. Об этом подробнее дальше.
Как подставить аргументы во View?
Используем хуки в своём модуле:
- hook_views_pre_view() - изменение в самом начале процессинга view.
- ИЛИ hook_views_pre_render() - воздействует на представление непосредственно перед его рендерингом, на этом этапе запрос уже выполнен, и для обработчиков уже выполнена фаза preRender(), поэтому все данные должны быть доступны.
В зависимости от ситуации используем один или другой хук.
Пример:
function mymodule_views_pre_view(ViewExecutable $view, $display_id, array &$args) {
if ('view_machine_name' == $view->id() && 'view_display_name' == $view->current_display) {
$nid = (null !== $args[0]) ? (int) $args[0] : null;
$limit = 24;
if (null !== $nid) {
/** @var SimilarNodeService $similar */
$similar = \Drupal::service('mymodule.similar_nodes');
$ids = $similar->getOrUpdate($nid, $limit);
$args[0] = join(',', $ids);
}
}
}
- проверяем, что машинное имя и имя дисплея соответствуют нашей вьюхе,
- получаем nid из аргумента.
Id можно получить еще и вот так:
$node = \Drupal::routeMatch()->getParameter('node');
if ($node instanceof NodeInterface) {
$nid = $node->id();
}
И тогда можно не привязываться к аргументам вьюхи.
Метод getOrUpdate() принимает два аргумента: id указанной ноды и лимит на количество похожих выводимых материалов.
Сначала метод смотрит, есть ли данные. Если есть - выводит их. Если нет - записываем новые данные и после этого выводим их.
public function getOrUpdate(int $nid, ?int $limit = self::LIMIT): array
{
$similar = $this->get($nid, $limit);
if (!empty($similar)) {
return $similar;
}
$similar = $this->getSimilar($nid);
if (empty($similar)) {
return [];
}
$this->add($nid, $similar);
$data = array_slice($similar, 0, $limit, true);
return array_keys($data);
}
Если данных в связанной таблице нет, то страница отработает медленно, но только один раз для первого пользователя её посетившего или если команда полного обхода еще не добралась до этого материала.
Далее, даже если сбрасывать кэш, данные в связанной таблице уже будут присутствовать и страница будет загружаться очень быстро.
Со временем данные для каждой ноды будут записаны в БД. Останется лишь периодически перезапускать обход, чтобы актуализировать информацию.
▲Итог
Важная мысль: оптимизация производительности сайта - это процесс.
Один из очевидных минусов, как Drupal, так и многих других "коробочных" CMS - стандартные методы ускорения загрузки страниц не всегда работают.
Нужно выходить из рамок системы управления и думать в плоскости разработки в целом.
После указанных в статье (и некоторых других) манипуляций, средняя скорость загрузки сократилась почти в три раза, с 5 секунд до приемлемых 1.6 - 1.9 секунд.
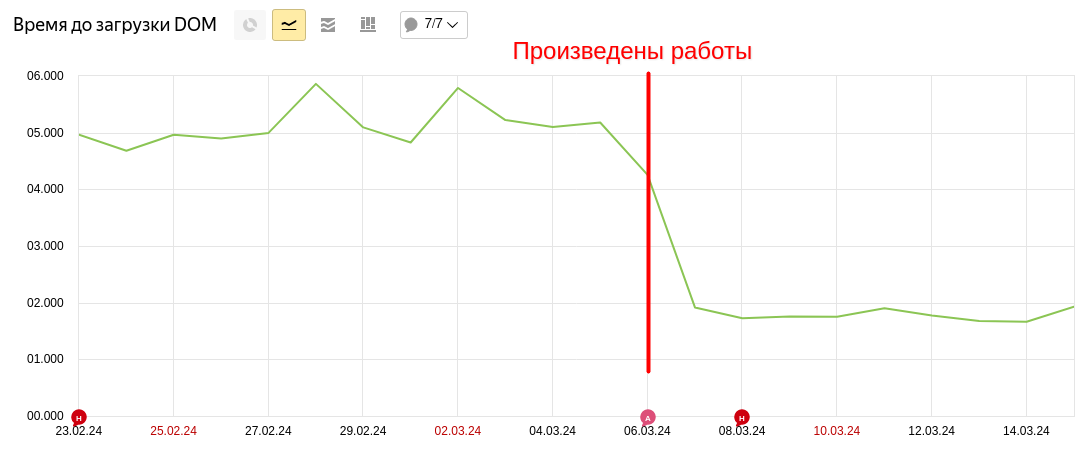
При этом есть еще некоторые точки роста. Например, осталось много тормозящих скриптов, но это уже для другой статьи.
▲Полезные ссылки
- Презентация в лёгкой, шуточной форме High Performance Drupal - Step by Step v 4 - https://events.drupal.org/sites/default/files/slides/4x%20High%20Performance%20Drupal%20-%20Step%20by%20Step%20v4.pdf
- High Performance сообщество на D.org, не особо активное, но есть, что почитать - https://groups.drupal.org/high-performance
- Бесплатная PDF книга High Performance Drupal, старенькая уже, 2015 год выпуска, но пусть будет для коллекции - https://www.academia.edu/11035886/High_Performance_Drupal
- Бесплатный курс Google Web Dev - Learn Performance - https://web.dev/learn/performance
- Справочник Fast Load Times всё с того же Web Dev - https://web.dev/explore/fast





Добавить комментарий